

MIKI Yoshihito from Sapporo City,Hokkaido., JAPAN, CC BY 2.0, via Wikimedia Commons
Why the Similarity Percentage of Chimp and Human DNA Is Deceptive
What do genome comparisons actually mean—and what does E. coli indicate?
“The DNA matches, the timing works, everything checks out.” — Talon from Disney/Pixar’s Ratatouille
Abstract
Evolutionists frequently cite the supposed 98%–99% similarity between human and chimpanzee DNA in support of their secular worldview.1 Evolutionists are impressed with such a high percent similarity at the DNA level between these two organisms, and therefore, we should also be convinced of common ancestry between humans and chimpanzees.2 Recently, a team of scientists sequenced DNA from apes and compared it with humans only to find a 12.5% to 13.5% difference (which really obscures their usual storytelling).3 Darwin originally suggested that his tree of life had “budding twigs” that eventually became separate species.4 While Darwin didn’t know DNA existed, modern evolutionists state that DNA sequences have only confirmed what Darwin originally said (addition of our knowledge of DNA to Darwin’s theory has led to the modern evolutionary synthesis, aka neo-Darwinism).5 Although the actual percent similarity between humans and chimpanzees is probably lower than 98%–99% (it is closer to 85%), the “98%–99%” has misled many into believing there was a common ancestor between humans and chimpanzees.6, 7 In reality, there is nothing concerning with these percentages because (1) humans descended from Adam and Eve and (2) the percentages are scientifically problematic because of misrepresentation and oversimplification of the data. The purpose of this article is to highlight why percentages (such as 98%–99%) do not make sense for understanding species relatedness and are primarily motivated by evolutionary motives. To demonstrate why the 98%–99% is not helpful for the origins topic, I will first describe a genome, how it is sequenced, and then use several examples of DNA sequences from my area of expertise: Escherichia coli.
 Photo by Eric Erbe, digital colorization by Christopher Pooley, both of USDA, ARS, EMU., Public domain, via Wikimedia Commons
Photo by Eric Erbe, digital colorization by Christopher Pooley, both of USDA, ARS, EMU., Public domain, via Wikimedia Commons
{kind=link}
What Is a Genome?
The genome is the entire DNA sequence for an organism—it contains all the adenines (A), cytosines (C), guanines (G), and thymines (T). The A’s , C’s, G’s, and T’s are arranged in a specific order to code for the genes but are also important in parts of the genome that act to regulate when certain genes are turned on/off (like a switch). When I was a college student, the evolutionary textbook for my molecular genetics class suggested that bacterial genomes were smaller than humans’ genomes because of descent with modification.8 However, Table 1 shows various genome sizes from viruses through humans. If Darwinian evolution were true, then there would be no exceptions like the largest genome on record belonging to a fern (notice also that the largest virus genome is larger than the smallest bacterial genome). The number of genomes that an organism carries is also different from organism to organism. On average, bacteria carry roughly one copy of their genome (often referred to as haploid), while humans carry two copies of the genome (called diploid).9 Even more interesting are certain plant species that carry even more genomes per cell, such as some strawberries that carry eight copies (called octaploid).10 Sometimes, genomes are referenced based on the percentage of G’s and C’s in the sequence (called G/C content). The most important aspect to a genome is the sequence of the letters because they code for the different proteins making up the organism.
Scientific name |
Genome Size (base pairs) |
|---|---|
Tobacco Mosaic Virus |
6,384 |
Mycoplasma genitalium (bacteria) |
580,070 |
Mimivirus |
1,181,404 |
Escherichia coli |
4,639,221 |
Saccharomyces cerevisiae (baker’s yeast) |
12,068,000 |
Sorangium cellulosum (myxobacterium) |
13,033,779 |
Caenorhabditis elegans (nematode) |
97,000,000 |
Arabidopsis thaliana (plant) |
125,000,000 |
Drosophila melanogaster (fruit fly) |
180,000,000 |
Mus musculus (mouse) |
2,500,000,000 |
Homo sapiens (humans) |
3,100,000,000 |
Protopterus annectens (African lungfish) |
40,500,000,000 |
Tmesipteris oblanceolata (fork fern) |
160,450,000,000 |
Table 1. Several genome sizes11
How Is DNA Sequenced and Compared?
Sequencing DNA became widespread in the 1970s with the discovery of the particular method pioneered by Fred Sanger (who won the Nobel prize for this discovery).12 Initially, DNA sequencing was complex, dideoxyribonucleotide triphosphates (ddNTPs) were placed in separate tubes and run in separate lanes on a radiograph gel. The next significant advancement with DNA sequencing came when different dyes were incorporated and recorded by a computer giving a readout. When the computers were added to the process, our ability to sequence entire genomes became easier. Initially, individual genes were sequenced, followed by entire genomes for viruses, before finally sequencing entire bacterial genomes. Today, the method of next generation sequencing (NGS) allows scientists to sequence multiple genomes simultaneously through either paired-end sequencing using an Illumina platform (see image using bacterial genome) or obtaining long-reads on something like a PacBio. When the human genome was originally sequenced, it took a team of dedicated researchers across several laboratories approximately 10 years to finish. Using today’s NGS, we can obtain a single human genome in one lab, from one machine, in just a few days. As a result, the cost of DNA sequencing has dropped and our access to DNA sequence has expanded exponentially.
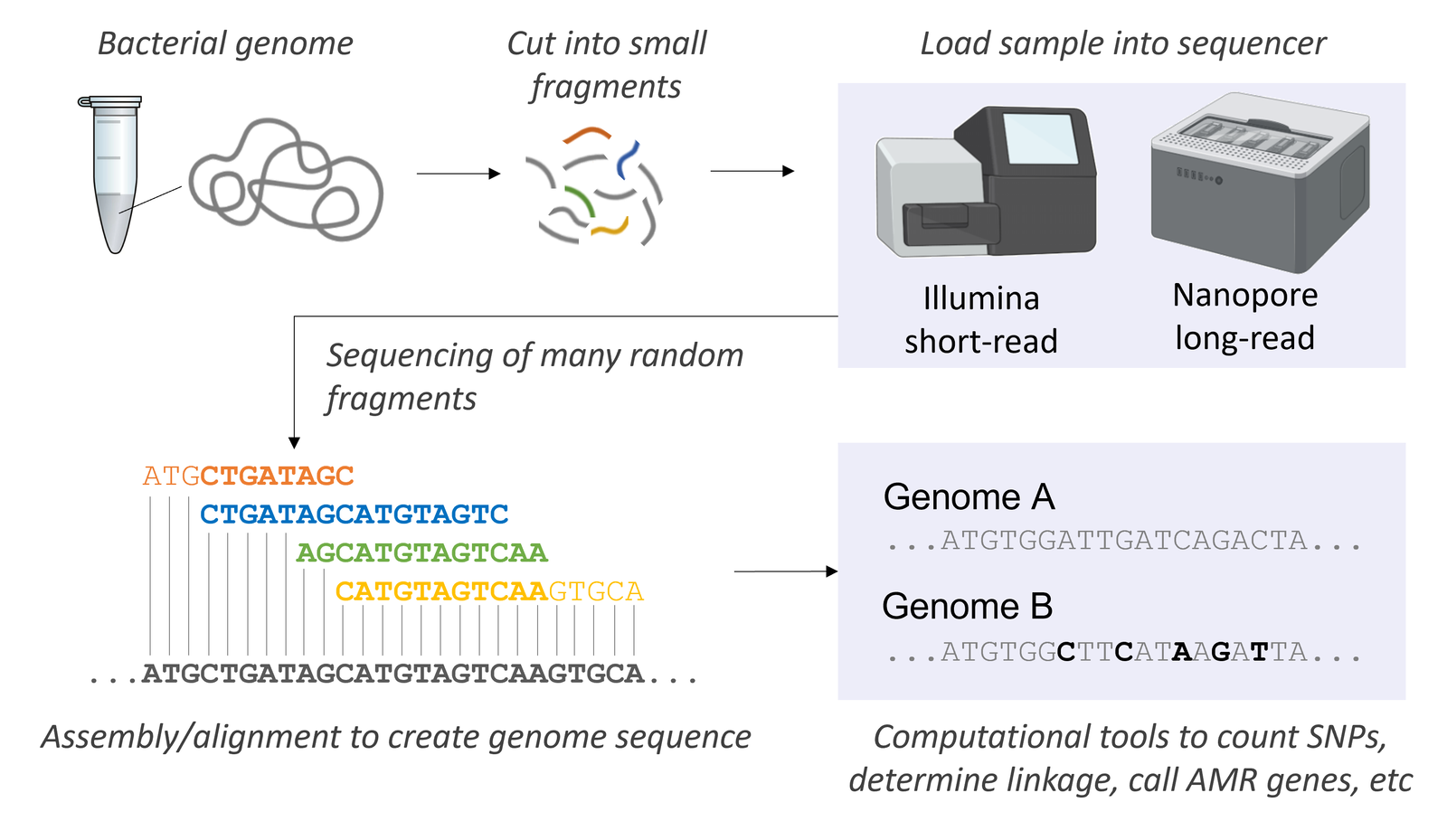
Nataschamt, CC BY-SA 4.0, via Wikimedia Commons
{kind=link}
Traditionally, scientists measure percent similarity for two DNA sequences (or more) using a computer algorithm called Basic Local Alignment Search Tool (or BLAST for short).13 The BLAST algorithm finds the maximal alignment between two DNA sequences and reports it as a percentage. However, it is important to distinguish two similar DNA sequences from two identical DNA sequences because similar and identical are not synonyms. Furthermore, there are sequences that cannot align using BLAST because the differences are so strong—so how can those be classified? Simply put: Sequences without any alignment are not classified as having any matches nor are they described otherwise—they are not addressed. In summary, there are identical sequences, similar sequences that can match to a certain extent, and sequences that have no sequence matching whatsoever. Let’s consider the simple bacterium Escherichia coli to understand the differences between identical and similar as it relates to DNA percentages.
What Escherichia coli Is: The Good and the Bad
Escherichia coli is the best understood organism on the planet. It was originally called Bacterium coli commune when first isolated by pediatrician Theodor Escherich in 1886.14 Some have said, “There are only two kinds of bacteria. One is Escherichia coli and the other is not.”15 It was identified as a commensal, enteric bacteria that we now know provides us with vitamin K. What identifies E. coli from other enterics is that it is a Gram-negative, facultative anaerobe (bacteria capable of respiring oxygen and other chemicals), ferments the carbohydrate lactose, and usually does not grow aerobically on citrate media (aka citrate negative).16 In the 1970s, Carl Woese began sequencing the 16S ribosomal RNA (rRNA) gene from organisms and used this for classification purposes (each species has a unique 16S sequence).17 Everything that meets these biochemical test requirements (with the exception of the genera Shigella spp. that are simply citrate positive) along with carrying the specific sequence for the 16S rRNA gene are classified as E. coli—including harmless ones (non-pathogens or commensals) and ones that cause disease (pathogens) (more below).18
What We Learned from Sequencing E. coli
The first E. coli genome sequenced was for the non-pathogenic serotype K-12 strain MG1655 originally isolated from a convalescing diphtheria patient (referred hereafter as MG1655) and was significant for its time.19, 20 MG1655 is used in biotechnology responsible for medical breakthroughs like insulin production for diabetics or industrial chemicals like acetone.21 The MG1655 genome is 4,639,221 base pairs (simplified in millions of base pairs as 4.64 Mbp) and has a GC-content of 50.8%. MG1655 is a Gram-negative, facultative anaerobe, fermenting lactose, is citrate negative, and its 16S rRNA gene sequence matches our understanding of E. coli. When MG1655 was first sequenced, most scientists thought that sequencing one strain of E. coli was sufficient to understand every strain of E. coli. It was not long before we began investigating more E. coli isolated from other sources that things began falling apart. But it is first important to discuss what scientists mean when they say that certain genomes share similar DNA sequences.
After sequencing the commensal MG1655, scientists sequenced the pathogenic E. coli known as O157:H7 strain EDL933 (referred hereafter as EDL933).22 EDL933 was isolated from an outbreak of hemolytic uremic syndrome in 1983.23 When EDL933 was sequenced, it was already known to have virulence factors (e.g., toxin genes and/or a pathogenicity island, which is a stretch of DNA carrying multiple toxins that were probably acquired from an outside source like a bacteriophage) that were absent from commensal E. coli (e.g., MG1655). In terms of how the EDL933 genome might compare with the genome of commensal MG1655, it was thought that the only difference between MG1655 and EDL933 would be the presence of virulence genes in EDL933 (both integrated on the bacterial chromosome as well as its plasmid pO157). To the contrary, the EDL933 genome size was considerably larger than the MG1655 genome (nearly 1Mbp!): The size of the EDL933 genome is 5,528,445 bp (with a plasmid, pO157, that is only 92,077 bp). Even the authors stated, “Our findings reveal a surprising level of diversity between two members of the species E. coli.”24 In looking at just the comparison between these two members of E. coli (from information provided in the EDL933 genome sequence publication), several things are already worth noting. If MG1655 and EDL933 have significant differences, then what do the differences mean? To address those differences, here is an example to help understand what is seen at the DNA level.
Apples and Oranges: Understanding Differences in DNA
Trying to understand differences in DNA between genomes can be like comparing apples to oranges. The reason making comparisons with DNA is difficult is partly based on words we choose to describe whether things are similar or not. When describing two genomes that are identical, it is easy to understand that there are no differences and that everything is the same 100% of the time. Using everyday objects like apples and oranges, saying that something is identical would mean that we are comparing two Red Delicious apples to each other. Whenever scientists use the word similar, there are two categories that this can fall into where they line up with some differences or when there is little basis for any comparison (which can sound confusing). The normal use of the word similarity would be like comparing a Red Delicious apple to a Granny Smith apple. Anyone can recognize that they are both apples, but the color of the skin is different, there is a slightly different taste, etc. Taking this analogy further, there are DNA sequences found in organisms that have a certain degree of similarity like this and yet still have DNA that cannot match anything else in the other organism. Using the example further with the apples, this would be where the proverbial comparing apples to oranges comes into play because the apples and oranges do not match color or flavor, but it can be said that they are both fruits.
In looking at DNA samples and trying to give a percentage, sometimes there is no way to make a real comparison. Sometimes, the only possibility is to say things like apples have a thin skin while oranges have a rind. The apple skin is not really similar to the rind, but what other way can we describe it? What percent of the apple skin compares with the orange rind? DNA similarities often fall into categories like this where one species will have DNA that is nowhere in a second species. Other times, the two species will be able to compare DNA sequences (e.g., having seeds in comparing apples and oranges), but sometimes they do not line up all the way and there are single letter differences in the code. In the following sections, we will examine these categories separately as they pertain to the genome sequences among various E. coli.
Initial Differences Among E. coli
The base pair difference between MG1655 and EDL933 is 889,224—this number represents about a 19.2% difference. Putting this difference another way, one in five nucleotides is different between these strains. Even with this many differences, both strains still share DNA (called a backbone) that is 4.1 Megabases. Having this common backbone means that there are base pairs unique to both commensal MG1655 and pathogenic EDL933—there are base pairs present in only MG1655 and base pairs present in only EDL933. From the backbone of the E. coli genome, there are 75,168 single nucleotide polymorphisms (today referred to as single nucleotide variants) between MG1655 and EDL933. The number of polymorphisms is less than a 2% difference in the parts of the genome that are highly similar between both strains.25 Keep in mind that both of these strains are still Gram-negative, facultative anaerobes, fermenting lactose, citrate negative, and have nearly identical 16S rRNA gene sequences (one nucleotide difference, still the same species by all measures)!
Second (and possibly most interesting), there are genes unique to the pathogen EDL933 besides the virulence factors. The authors of the paper for the genome sequence of EDL933 stated that there were 528 genes unique to MG1655 and 1,387 “new genes” in EDL933. Some of the unique genes in EDL933 allow it the ability to grow on the carbohydrate N-aceltylgalactosamine (i.e., MG1655 lacks these genes entirely). The idea of knowing what defines E. coli (by whether it is a Gram-negative, facultative anaerobe, fermenting lactose, is citrate negative, and its 16S rRNA gene sequence) began to unravel as we entertained the idea that E. coli carried a certain set of “required” genes and could also carry other miscellaneous genes without falling outside the traditional definition. It seems that there are certain sets of genes always found inside of what is called E. coli in addition to certain sets of genes that are never found in an E. coli genome.
Third, only 911 proteins were identical between the ~4,600 genes in MG1655 and ~5,600 genes in EDL933—that’s 19.8% in MG1655 and 16.2% in EDL933. The percentages of identical proteins means that approximately only one in five proteins is identical (100% the same) for two members of the same species! Even more surprising than how few identical proteins exist between these strains is that the authors suggest a most recent common ancestor between these E. coli was 4.5 million years ago (which is not based on Scripture). For only 911 proteins being identical after 4.5 million years is shocking because both strains still meet the core definition for what makes E. coli. Given these three observations, some initial conclusions can be drawn before updating this information with even more recent genome sequences available.
Measuring percent similarity between two strains of E. coli is complicated because of the different sizes of their genomes (the number of base pairs for MG1655 divided by the number of base pairs for EDL933, which is 83.915%) or the number of identical base pairs between the core E. coli backbone they identified (the total backbone minus the single nucleotide polymorphisms divided by the core backbone base pairs, which is 98.167%). When I was in graduate school, we asked ourselves whether MG1655 was the same as EDL933 for these reasons. We told ourselves that they were similar where they were identical but that they remained different strains of E. coli because of how many gene differences there are (and it was not just the virulence genes that made these strains so different—e.g., I published significant differences in what they competed for during colonization of the mammalian intestine).26 The idea of any given bacterial species containing nearly identical DNA sequences was becoming unhinged with just the second E. coli genome sequenced. But what about additional E. coli genomes to sequence? Does more DNA sequencing provide the answer?
Even Less DNA Similarity Among E. coli
The third E. coli genome sequenced was a strain that causes urinary tract infections called CFT073 (serotype O6:H1:K? ).27 The genome of CFT073 has 5,231,428 base pairs (without a plasmid, unlike EDL933) and was significantly different from both MG1655 and EDL933. The authors stated in the second sentence of the paper abstract: “A three-way genome comparison of the CFT073, enterohemorrhagic E. coli EDL933, and laboratory strain MG1655 reveals that, amazingly, only 39.2% of their combined (nonredundant) set of proteins actually are common to all three strains” (see Figure 1). In this three-way comparison, the idea of a core backbone to the genome decreased to about 40% because of an additional E. coli genome being compared. Take note of what the authors of the paper were suggesting: Modern day members of the same species can have a percent similarity as low as 40%! Remember that the current positivistic philosophy of modern science thought they could rescue percent similarity by sequencing more strains of E. coli. But did this extra sequencing help the evolutionary problems for a percent similarity used within a given species? Keep in mind: E. coli is the best understood organism on the planet. How much worse can a percent similarity get?
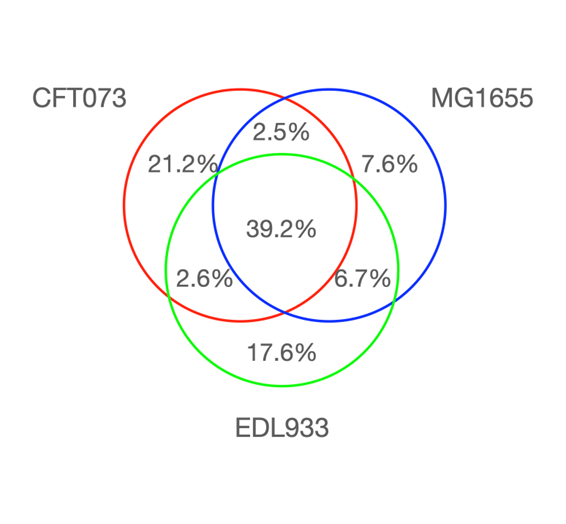 Figure 1. Genome comparison between MG1655, EDL933, and CFT073 adapted from Welch RA et al. 2002.
Figure 1. Genome comparison between MG1655, EDL933, and CFT073 adapted from Welch RA et al. 2002.
While several other E. coli genome sequences were published around the time of CFT073, the first paper reporting sequences of multiple E. coli strains had eight genome sequences and compared them with the other available E. coli genomes (a total of 17 genomes were included for this comparison).28 In performing this analysis, the authors found that all E. coli genomes sequenced only shared ~2,200 genes—though the gene content for each genome ranged from 4,238 genes (MG1655) up to 5,589 (CFT073). From their comparative genomic analysis, the authors concluded that there may be approximately 13,000 different genes that could be found in all E. coli genomes on the planet today—while still all being called E. coli.
About the time of the previous comparative genomic analysis, a new sequencing technology was developed that allowed more genomes to be sequenced with greater frequency and efficiency (called next generation sequencing, or NGS). The labs that reported the initial eight genomes have since obtained over 600 genomes (Table 1). Of the over 600 sequences they deposited in Genbank, no two were identical. If we began the process of comparing genomes by using Venn diagrams, the first couple genomes sequenced only had between 60% and 70% similarity or overlap. As there were more genomes sequenced, the area of overlap has continued to decrease. However, the amount of overlap in that Venn diagram has reached a limit given the number of E. coli genome sequences available. Several years ago, I contacted one of the genome scientists to ask how many nucleotides he had found to define E. coli. The response I received was that E. coli has about 2.5 million nucleotides. When he said 2.5 million nucleotides, consider that those 2.5 million did not need to be in order on the genome but only that they were present somewhere in the genome for something we know and call E. coli.
Paper |
# Genomes Sequenced |
Link |
|---|---|---|
Comparative genomic analysis provides insight into the phylogeny and virulence of atypical enter-pathogenic Escherichia coli strains from Brazil |
106 |
https://pubmed.ncbi.nlm.nih.gov/32479541/ |
Conservation and global distribution of noncanonical antigens in enterotoxigenic Escherichia coli |
46 |
https://pubmed.ncbi.nlm.nih.gov/31756188/ |
Temporal variability of Escherichia coli diversity in the gastrointestinal tracts of Tanzanian children with and without exposure to antibiotics |
240 |
https://pubmed.ncbi.nlm.nih.gov/30404930/ |
Characterization of the pathogenome and phylogenomic classification of enteropathogenic Escherichia coli of the O157:non-H7 serotypes |
6 |
https://pubmed.ncbi.nlm.nih.gov/25962987/ |
Draft genome sequences of nine enter-pathogenic Escherichia coli strains from Kenya |
9 |
https://pubmed.ncbi.nlm.nih.gov/24926061/ |
Draft genome sequences of three O157 enteropathogenic Escherichia coli isolates |
3 |
https://pubmed.ncbi.nlm.nih.gov/24926061/ |
Refining the pathovar paradigm via phylogenomics of the attaching and effacing Escherichia coli |
114 |
https://pubmed.ncbi.nlm.nih.gov/23858472/ |
Draft genome sequences of five recent human uropathogenic Escherichia coli isolates |
5 |
https://pubmed.ncbi.nlm.nih.gov/23821517/ |
Draft genome sequences of the diarrheagenic Escherichia coli collection |
15 |
https://pubmed.ncbi.nlm.nih.gov/22582382/ |
Draft genome sequences of the Escherichia coli reference (ECOR) collection |
72 |
https://pubmed.ncbi.nlm.nih.gov/30533715/ |
Total |
616 |
Table 2. List of E. coli genome sequences available by searching through PubMed and Genbank. This list is not exhaustive as of the date of publication.
If No Two E. coli Genomes Are Identical , Then Humans and Chimpanzees Did Not Share Common Ancestors
Our understanding of the E. coli genome has advanced significantly in recent years. To date, there are 29,031 whole genome sequences for Escherichia coli in Genbank (including scaffold, chromosome, or complete for the filter, retrieved on May 4, 2025, https://www.ncbi.nlm.nih.gov/datasets/genome/?taxon=562&assembly_level=1:3).29 Most importantly, no two E. coli genomes are identical. Among those genomes most closely related might be the strain that I sequenced, which was passaged through a mouse intestine and found to have minor differences compared to its original genome.30 If we had stopped sequencing E. coli genomes after the first one (MG1655), we might have a slightly different perspective about what E. coli is. However, by sequencing the vast number of E. coli genomes, we have a sufficient number of genomes in Genbank to draw conclusions about genome similarities that extends beyond understanding what E. coli is—we can learn how useful genome similarities are in the origins debate.
By sequencing the vast number of E. coli genomes, we have a sufficient number of genomes in Genbank to draw conclusions about genome similarities that extends beyond understanding what E. coli is—we can learn how useful genome similarities are in the origins debate.
First, the understanding we had about what defines E. coli from traditional biochemical tests is valid still: a Gram-negative, facultative anaerobe, fermenting lactose, that is usually citrate negative (Bergey’s manual).31 If we think about it, the bigger surprise should be expecting sequencing genomes to tell us something different than what the central dogma of molecular biology upholds: Enzymes have DNA sequences that should be relatively similar. Perhaps the shock is with the differences in gene content and regulatory regions. The idea of allowing the central dogma of molecular biology to inform our thoughts on percent similarities extends well beyond E. coli and into every living thing on the planet.
Consider the visible anatomical similarities between humans and chimpanzees as an example of expecting DNA similarities. If there are anatomical similarities and DNA codes for structural features in organisms, then the expectation is that there will be significant DNA sequence similarities between these organisms (saying there are no DNA similarities would violate our anatomical observations and the central dogma of molecular biology). Second, the number of genes defining E. coli fits well within the number of known nucleotides (i.e., the 2.5 million), but there might be value in modifying the E. coli definition—it might also be helpful to define E. coli by what it cannot do because it never has those genes. For example, E. coli has never been found to perform photosynthesis, methanogenesis, grow on polysaccharides, or glow in the dark. In comparing humans with other living things, we have to acknowledge some simple observations like our inability to make a cell wall made of cellulose. These functions are never present in the E. coli that we have been testing biochemically for years and is worth considering inclusion in the definition of what E. coli is. Upon closer analysis, we already can see that E. coli is usually citrate negative, but why not also include that E. coli is photosynthesis negative? Including other features helps define what we are able to see about E. coli in the mammalian intestine and marine ecosystems.32 Finally, the percent differences for all E. coli genomes can vary by as much as half and still be called the same organism because it shares the same 2.5 million nucleotides. There are some profound implications for this final point as it relates to percent similarities use for so-called human evolution and comparisons with nonhuman primate genomes.
Summing It Up
The percent differences for all E. coli genomes can vary by as much as half.
The main conclusion is that percent similarities between biblical kinds (or taxonomic families) carry little significance (unlike what evolutionists would have us think). According to evolutionary estimates, E. coli came into existence between 10 and 50 million years ago. Keep in mind that E. coli is present in all land animals and the majority of fish in the oceans, so evolutionists would need to consider coevolution of these organisms since these are symbiotic relationships. If coevolution is how these symbiotic relationships must happen, we must keep in mind that bacteria are supposed to be proof of evolution happening today. What does not make sense is that a single-cell bacterium like E. coli remains the same for 10 to 50 million years since evolutionists claim that bacteria evolve today rapidly. But if the bacteria are evolving rapidly, can there be any meaning behind a similarity between a human and a chimpanzee (or other nonhuman primate) on that same timeline? If the bacteria evolve quickly, then the humans and chimpanzees must also evolve quickly.33 The issue centers on the evolutionists’ usage of these percent similarities as part of their argument. Furthermore, it must be highlighted that E. coli has a far lower percentage of similarity among itself (near 50%, depending on the strains) as a single species than humans and chimpanzees have between themselves by either the creationist or evolutionist estimates (between 80% to 98%–99%). That amount of change in a genome sequence happening for something like bacteria means that genomic entropy is real.34 And if we know that there is such wide genetic diversity in E. coli and that it evolves quickly, then the timescale for humans and chimpanzees must be much shorter than previously thought. A difference of 1–2% cannot exist for 10–50 million years because organisms like E. coli have evolved (in their worldview) and have far greater percent difference between the organisms. Using this evolutionary logic in drawing a conclusion from a supposed 1–2% difference would put humans and chimpanzees having only been created within the past several thousand years (and I doubt that is what they are trying to promote).35
The Numbers Game
A related issue that must be addressed by evolutionists concerning these vanishingly small genome differences is that there could be an organism with only 1% similarity (for an outlandish example) that shares common ancestry with other organisms. Let’s pretend that organism A and organism B are “similar” and share 1% of the genome, which is 1,000,000,000 base pairs in size. Having a 1% similarity means that 10,000,000 nucleotides are the same. Looking at only numbers, the use of percent similarity obscures truly big differences. For example, it is generally thought that bathroom cleaning products are effective at killing 99.9% of the germs (Figure 2). However, most people do not realize that 99.9% of the millions of bacteria on a surface still means that there are thousands of bacteria left on that same surface—the percentage is misleading in advertising as much as it is misleading in an evolutionary worldview. And just like we should not abandon the use of disinfectants, we should also not abandon using percent similarities. We must remind ourselves of the limitations of each and use them within reason. In contrast with the evolutionary worldview, the biblical concept of kind fits well with a limited number of DNA nucleotides that comprises the genome for a given kind. Given this extreme perspective of thought, we should realize and call out evolutionists because they would cite a 1% similarity between organisms as proof of evolution if they needed to because it is not about the evidence.
 Figure 2. Disinfectants often claim to kill 99.9% of the germs. But the 99.9% number obscures how many germs are actually left behind. Still use disinfectant, but do not assume it is as effective as you may think.
Figure 2. Disinfectants often claim to kill 99.9% of the germs. But the 99.9% number obscures how many germs are actually left behind. Still use disinfectant, but do not assume it is as effective as you may think.
DNA Similarities Support Design
Genome comparisons and percent similarities demonstrate the faith that we exercise: either in God’s Word or man’s word. No amount of evidence will convince an evolutionist just like the Pharisees who witnessed the healing of the sick and accused Jesus of being demon possessed. Ultimately, Christians can stand confidently on the authority of Scripture because all good science supports Scripture.
Answers in Depth
2025 Volume 20

Answers in Depth explores the biblical worldview in addressing modern scientific research, history, current events, popular media, theology, and much more.
Browse VolumeFootnotes
- American Museum of Natural History, “DNA: Comparing Humans and Chimps,” accessed May 6, 2025, https://www.amnh.org/exhibitions/permanent/human-origins/understanding-our-past/dna-comparing-humans-and-chimps; Bill Nye, Undeniable: Evolution and the Science of Creation (New York: St. Martin’s Press, 2014).
- Technically, the evolutionists change their minds on whether humans supposedly share more common ancestry with chimpanzees or some other nonhuman primate. Though their efforts at being accurate are applaudable, they are on an ever-changing foundation of man’s ideas. Creationists should expect information like this to change regularly and accommodate their worldview more than God’s Word (i.e., reality).
- Ham, Ken, “Study Finds Chimp DNA Is Not ‘99% Identical’ to Ours,” Answers in Genesis, May 27, 2025, https://answersingenesis.org/genetics/dna-similarities/study-finds-chimp-dna-not-identical-ours/.
- Darwin, C., On the Origin of the Species by Means of Natural Selection, or Preservation of Favoured Races in the Struggle for Life (London: John Murray, 1859).
- Behe, M. J., Darwin’s Black Box: The Biochemical Challenge to Evolution (New York: Free Press, 2006).
- Tomkins, J., “Comparison of 18,000 De Novo Assembled Chimpanzee Contains to the Human Genome Yields Average BLASTN Alignment Identities of 84%,” Answers Research Journal 11 (2018): 205–209.
- Some mentioned humans share DNA with bananas. Most of these claims are simply to make headlines and does not give a true sense of common ancestry from their own worldview. Consider when Bill Nye debated Ken Ham the second time and discussed this very topic: https://answersingenesis.org/blogs/ken-ham/2016/07/21/bill-nye-and-bananas/.
- Griffiths, A. J. F., J. H. Miller, D. T. Suzuki, R. C. Lewontin, and W. M. Gelbart, Introduction to Genetic Analysis, 7th edition (New York: W. H. Freeman, 1999).
- Clark, M. A., M. Douglas, and J. Choi, Biology 2e (Houston: OpenStax, 2018), https://openstax.org/books/biology-2e/pages/1-introduction.
- Folta, K. M., C. R. Barbey, “The Strawberry Genome: A Complicated Past and Promising Future,” Horticulture Research 6, no. 97 (2019): https://doi.org/10.1038/s41438-019-0181-z.
- In order from top to bottom:
Ohno, T., M. Aoyagi, Y. Yamanashi, H. Saito, S. Ikawa, T. Meshi et al., “Nucleotide Sequence of the Tobacco Mosaic Virus (Tomato Strain) Genome and Comparison with the Common Strain Genome,” Journal of Biochemistry 96, no. 6 (1984): 1915–1923, https://doi.org/10.1093/oxfordjournals.jbchem.a135026.
Fraser, C. M., J. D. Gocayne, O. White, M. D. Adams, R. A. Clayton, R. D. Fleischmann, et al., “The Minimal Gene Complement of Mycoplasma genitalium,” Science 270, no. 5235 (1995): 397–403, https://doi.org/10.1126/science.270.5235.397.
Raoult, D., S. Audic, C. Robert, C. Abergel, P. Renesto, H. Ogata et al., “The 1.2-Megabase Genome Sequence of Mimivirus,” Science 306, no. 5700 (2004): 1344–1350, https://doi.org/10.1126/science.1101485.
Blattner, F. R., G. Plunkett, C. A. Bloch, N. T. Perna, V. Burland, M. Riley et al., “The Complete Genome Sequence of Escherichia coli K-12,” Science 277, no. 5331 (1997): 1453–1462, https://doi.org/10.1126/science.277.5331.1453.
Goffeau, A., B. G. Barrell, H. Bussey, R. W. Davis, B. Dujon, H. Feldmann et al., “Life with 6000 Genes,” Science 274, no. 5287 (1996): 546–567, https://doi.org/10.1126/science.274.5287.546.
Schneiker, S., O. Perlova, O. Kaiser, K. Gerth, A. Alici, M. O. Altmeyer et al., “Complete Genome Sequence of the Myxobacterium Sorangium Cellulosum,” Nature Biotechnology 25, no. 11 (2007): 1281–1289, https://doi.org/10.1038/nbt1354.
The C. Elegans Sequencing Consortium, “Genome Sequence of the Nematode C. elegans: A Platform for Investigating Biology,” Science 282, no. 5396 (1998): 2012–2018, https://doi.org/10.1126/science.282.5396.2012.
Arabidopsis Genome Initiative, “Analysis of the Genome Sequence of the Flowering Plant Arabidopsis thaliana,” Nature 408, no. 6814 (2000): 796–815, https://doi.org/10.1038/35048692.
Adams, M. D., S. E. Celniker, R. A. Holt, C. A. Evans, J. D. Gocayne, P. G. Amanatides et al., “The Genome Sequence of Drosophila melanogaster,” Science 287, no. 5461 (2000): 2185–2195, https://doi.org/10.1126/science.287.5461.2185.
Mouse Genome Sequencing Consortium, R. H. Waterston, K. Lindblad-Toh, E. Birney, J. Rogers, J. F. Abril et al., “Initial Sequencing and Comparative Analysis of the Mouse Genome,” Nature 420, no. 6915 (2002): 520–562, https://doi.org/10.1038/nature01262.
National Library of Medicine, Genome Assembly GRCh38.p2, accessed May 13, 2025, https://www.ncbi.nlm.nih.gov/datasets/genome/GCF_000001405.28/#/st.
Schartl, M., J. M. Woltering, I. Irisarri, K. Du, S. Kneitz, M. Pippel et al., “The Genomes of All Lungfish Inform on Genome Expansion and Tetrapod Evolution,” Nature 634, no. 8032 (2024): 96–103, https://doi.org/10.1038/s41586-024-07830-1.
Fernández, P., R. Amice, D. Bruy, M. J. M. Christenhusz, I. J. Leitch, A. L. Leitch et al., “A 160 Gbp Fork Fern Genome Shatters Size Record for Eukaryotes,” iScience 27, no. 6 (2024): 109889, https://doi.org/10.1016/j.isci.2024.109889. - A member of my PhD committee (Bruce A. Roe) went to Fred Sanger’s lab to learn this technology and brought it back to the US.
Sanger, F., S. Nicklen, and A. R. Coulson, “DNA Sequencing with Chain-Terminating Inhibitors,” Proceedings of the National Academy of Sciences of the United States of America 74, no. 12 (1977): 5463–5467, https://doi.org/10.1073/pnas.74.12.5463. - Altschul, S. F., W. Gish, W. Miller, E. W. Myers, and D. J. Lipman, “Basic Local Alignment Search Tool,” Journal of Molecular Biology 215, no. 3 (1990): 403–410, https://doi.org/10.1016/S0022-2836(05)80360-2.
- Escherich, T., Die Darmbakterien des Säuglings und ihre Beziehungen zur Physiologie der Verdauung (Stuttgart: Verlag von Ferdinand Enke, 1886).
- Downie, J., and J. Young, “The ABC of Symbiosis,” Nature 412, no. 597–598 (2001): https://doi.org/10.1038/35088167.
- Holt, J. G., et al., Bergey’s Manual of Determinative Bacteriology (Williams & Wilkins,1994).
- Woese, C. R., and G.E. Fox, “Phylogenetic Structure of the Prokaryotic Domain: The Primary Kingdoms,” Proceedings of the National Academy of Sciences USA 74, no. 11 (1977): 5088–5090.
- The main exceptions for the biochemical test requirements belong to the genus Shigella spp. The Shigellae are really just E. coli that remained citrate positive over time. Traditionally, E. coli are usually defined as being citrate negative, but there are even some cases of citrate positive E. coli (though rare).
- Technically, the first bacterial genome sequenced belonged to the cause of the common ear infection (Haemophilus influenzae). Fleischmann, R. D., M. D. Adams, O. White, R. A. Clayton, E. F. Kirkness, A. R. Kerlavage et al., “Whole-Genome Random Sequencing and Assembly of Haemophilus influenzae Rd.,” Science 269 (1995): 496–512.
- Here is the citation for MG1655: Blattner et al., “Complete Genome Sequence of Escherichia coli K-12.”
- For questions about GMOs from a biblical perspective, you can read my book chapter here: Andrew Fabich, “Are GMOs Ethical?,” in The New Answers Book 4 (Green Forest, AR: Master Books, 2013),
https://answersingenesis.org/biology/plants/are-genetically-modified-organisms-wrong/?srsltid=AfmBOooBON4bZ__sTao0rSo3pfHY7ft3fcejyHIs9stvkx--nLXrvDYi. - Perna, N. T., G. Plunkett, V. Burland, B. Mau, J. D. Glasner, D. J. Rose, et al., “Genome Sequence of Enterohaemorrhagic Escherichia coli O157:H7,” Nature 409, no. 6819 (2001): 529–533, https://doi.org/10.1038/35054089.
- Wells, J. G., B. R. Davis, I. K. Wachsmuth, L. W. Riley, R. S. Remis, R. Sokolow, et al., “Laboratory Investigation of Hemorrhagic Colitis Outbreaks Associated with a Rare Escherichia coli Serotype,” Journal of Clinical Microbiology 18 (1983): 512–520.
- Perna et al., “Genome Sequence of Enterohaemorrhagic Escherichia coli O157:H7.”
- Having less than 2% polymorphisms for the DNA differences is not significant largely because of redundancy built in the genetic code. Further, some of these differences occur in places outside of key locations in enzymes such as the catalytic site. Many of these polymorphisms do not negatively affect overall metabolism, but there are minor variations that can be detected among these two strains.
- Fabich, A. J., S. A. Jones, F. Z. Chowdhury, A. Cernosek, A. Anderson, D. Smalley et al., “Comparison of Carbon Nutrition for Pathogenic and Commensal Escherichia coli Strains in the Mouse Intestine,” Infection and Immunity 76, no. 3 (2008): 1143–1152, https://doi.org/10.1128/IAI.01386-07.
- Welch, R. A., V. Burland, G. Plunkett, P. Redford, P. Roesch, D. Rasko et al., “Extensive Mosaic Structure Revealed by the Complete Genome Sequence of Uropathogenic Escherichia coli,” Proceedings of the National Academy of Sciences of the United States of America 99, no. 26 (2002): 17020–17024, https://doi.org/10.1073/pnas.252529799.
- Rasko, D. A., M. J. Rosovitz, G. S. Myers, E. F. Mongodin, W. F. Fricke, P. Gajer et al., “The Pangenome Structure of Escherichia coli: Comparative Genomic Analysis of E. coli Commensal and Pathogenic Isolates,” Journal of Bacteriology 190, no. 20 (2008): 6881–6893, https://doi.org/10.1128/JB.00619-08.
- Scaffold, chromosome, and complete are three choices to select when uploading a DNA sequence into Genbank. A scaffold is a DNA sequence that was pieced together using another known DNA sequence as a template. A chromosome indicates that it is the majority of the DNA sequence for a large stretch of DNA that cannot be a plasmid sequence. A complete genome means that there are no gaps in the sequence uploaded into Genbank and has nothing else to do for curating purposes.
- Fabich, A. J., M. P. Leatham, J. E. Grissom, G. Wiley, H. Lai, F. Najar et al., “Genotype and Phenotypes of an Intestine-Adapted Escherichia coli K-12 Mutant Selected by Animal Passage for Superior Colonization,” Infection and Immunity 79, no. 6 (2011): 2430–2439, https://doi.org/10.1128/IAI.01199-10.
- Holt, J. G., et al., Bergey’s Manual of Determinative Bacteriology, 9th ed. (Baltimore, MD: Lippincott Williams & Wilkins, 1994).
- E. coli can be thought of as a scavenger because it does not have the ability to produce its own carbohydrates, nor can it break down many polysaccharides in nature. E. coli relies on other organisms like Bacteroidetes spp. to break down complex polysaccharides and live on what the Bacteroidetes spp. do not consume.
- Some evolutionists might claim that generation time is vastly different along with other environmental factors. If that is the case, then that means that the rate of mutation itself depends on the environmental conditions and not being a matter of selective pressure (going against evolutionary theory). And if we give them the benefit of the doubt, the next conclusion is one that creationists have been predicting for a long time: Different species have different mutation rates. Evolutionists need to think hard about this issue before picking their response.
- Sanford, J. C., Genetic Entropy & the Mystery of the Genome, 4th ed. (New York: FMS Publications, 2014).
- Evolutionists have long been citing bacterial mutation rates as evidence of macroevolution. They are free to argue that bacteria’s mode of reproduction is simpler, but they must then quit using bacterial mutation rates as evidence for human/chimpanzee mutation rates. You cannot have your proverbial mutational cake and eat it too.
Support the creation/gospel message by donating or getting involved!

Answers in Genesis is an apologetics ministry, dedicated to helping Christians defend their faith and proclaim the good news of Jesus Christ.
- Customer Service 800.778.3390
- Available Monday–Friday | 9 AM–5 PM ET
- © 2026 Answers in Genesis