
Chapter 6
The Origin of Microorganisms
by
Roger Patterson
on
March 29, 2007
Republished with permission and featured in
Evolution Exposed: Biology
Evidence for the origin of life confirms the biblical account that God supplied the information for complex features when He created each kind.
In tracking the emergence of the eukaryotic cell one enters a kind of wonderland where scientific pursuit leads almost to fantasy. Cell and molecular biologists must construct cellular worlds in their own imaginations. ... Imagination, to some degree, is essential for grasping the key events in cellular history.–B.D. Dyer and R.A. Obar, Tracing the History of Eukaryotic Cells,
Columbia University Press, 1994, pp. 2–3
What You Will Learn
According to evolution, once life had spontaneously formed on earth it underwent amazing changes. The exact pattern of these changes is greatly disputed, and molecular evidence is calling the accepted order of bacterial evolution into question. In the evolutionary story, single-celled organisms had to develop ways to cope with an ever-changing environment. As oxygen and radiation levels changed, new information appeared to accommodate these changes in the environment. Multicellular life flourished in the “prehistoric” oceans, and certain organisms began to use others for food. Eventually, photosynthesis allowed an alternative lifestyle, and fungi and plants appeared. The appearance of sexual reproduction offered another benefit that was exploited by certain organisms.
The problem with the above account is that it is all just a story. Virtually no evidence supports the statements, but “they must have happened” or life wouldn’t exist in the forms we see today. This circular reasoning lends little support to the theory of evolution. The amazing diversity that appears “suddenly” in the geologic Cambrian Period (known as the Cambrian explosion) is another difficulty for evolutionists to explain. This sudden appearance of complex multicellular organisms is evidence in favor of fully formed complex organisms being created at one point in history. Despite the fact that evolution can accommodate explanations of the usefulness of certain features, it cannot explain—with supporting evidence—how these features came into existence. The evidence confirms the biblical account that God supplied the information for these complex features when He created each kind.
What Your Textbook Says about the Origin of Microorganisms
| Evolutionary Concept | Glencoe | PH-Campbell | PH-Miller | Holt | Articles |
|---|---|---|---|---|---|
| Prokaryotes are more “primitive” than eukaryotes and occur earlier in the fossil record. | 173 | 114 | 427 | 58, 259, T259 | 6:1 |
| Prokaryotes appear 3.5 billion years ago as fossil stromatolites. Eukaryotes appear later in the fossil record. | 377, 456 | 300, 356 | 173 | 57, 258 | 6:1, 6:2 |
| Multicellular organisms evolved many times over 700 million years ago. | — | — | 498 | 261, 416, 461, 618 | 6:3 |
| Fungi evolved from eukaryotes 400 million years ago. | 458 | — | — | 482 | 3:7 |
| Eubacteria and archaebacteria evolved from a common ancestor based on interpretations of molecular evidence. | 484 | 361 | 472 | 258, 413– 414 | 5:5, 6:4 |
| Organisms evolved to live in an environment with increasing oxygen due to photosynthesis. | 490–491 | 366 | 426 | — | 5:5, 6:5 |
| Protists are generally grouped by characteristics because their evolutionary relationships are very complex and based on DNA evidence. | — | T378, 380– 381, 396–397 | 498 | 461 | 3:6, 3:7 |
| Protists evolved from eukaryotes over a billion years ago. | 520–521 | 395–397 | 498, 506 | 460 | 3:7 |
| Fungi, plants, and animals all evolved from protists hundreds of millions of years ago. | 543 | 395 | 536 | 261, 460 | 3:6, 3:7 |
| Fungi evolved with plants in a symbiotic relationship. | — | 411 | 537, T537, 541 | — | 3:6 |
| Mitochondria and chloroplasts evolved as primitive prokaryotes and were absorbed by other cells—known as the Endosymbiont Hypothesis. | 384–385 | T128, 395–397 | 171, 180, T180, 427, T427 | 65–66, 259–260, T260 | 6:6 |
| Sexual reproduction first evolved in protists. | 318 | 193 | 428 | 461 | 3:6, 6:7 |
Note: Page numbers preceded by “T” indicate items from the teacher notes found in the margins of the Teacher’s Edition.
What We Really Know about the Origin of Microorganisms
Evolutionists must explain how cells, once they emerged from lifeless matter, diversified into the many life forms we see today. It is supposed that some extinct ancestor of the archaebacteria and eubacteria developed the necessary biologic machinery to survive in diverse situations. There is no evidence for this transformation other than the interpretation of molecular studies extrapolated backwards for billions of years. One major problem for the development of early unicellular organisms is the presence of oxygen in the atmosphere. It is becoming clear that there is no evidence from geology that there was ever a time in earth’s history when oxygen wasn’t present. The earliest fossil organisms are of oxygenproducing bacteria that form structures known as stromatolites; so any previous organisms must come from imagination, not evidence.
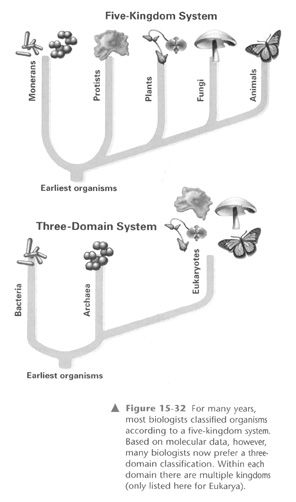
(PH-Campbell 348) As more information is gathered about the molecular structure of different organisms, the way phylogenetic trees are structured is changing. Recent research and papers on the topic of ancestry are making it harder for evolutionists to determine the line of descent. The data—when interpreted in an evolutionary framework—seems to be pointing to a maze of interconnecting lines and not a single tree with distinct branches.
As bacteria continued to evolve on the primitive earth, they supposedly developed many complex internal structures, what we call organelles today, and supported them inside membranes. The nucleus formed and became enclosed in a membrane with selective proteins that maintain the integrity of the DNA.
Another popular theory is that the mitochondria and chloroplasts are actually endosymbionts—organisms that were “eaten” by a host, but not digested. Somehow, these ingested cells reproduced in harmony with the host, providing some benefit to each. Eventually, DNA was passed from the ingested cell to the nucleus of the host, and the cells became intertwined forever. The fact that there is no real evidence to support this idea is generally ignored. Evidence against the theory is ignored because there is no other accepted naturalistic explanation that accounts for the presence of these organelles.
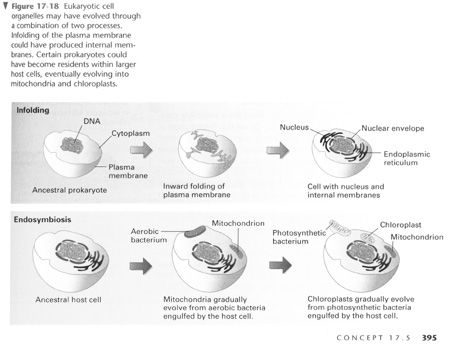
(PH-Campbell 395) The process of evolving from a “simple” prokaryote into a “complex” eukaryote is not documented in the fossil record. Despite the lack of evidence, sequences like the one shown in this picture are presented as an explanation in the evolutionary story. It is believed by many evolutionists that the mitochondria and chloroplasts found in eukaryotic cells were actually free-living bacteria that were absorbed but not digested by an ancestral cell line. The endosymbiont hypothesis uses molecular data as support, but the explanation is full of loose language that “may suggest” how the process happened over millions of years.
As life continued to evolve, multicellular organisms formed as colonies of cells cooperated for mutual benefit. Exactly how a colony of individuals produced a reproductive method that forms the many different cell types needed is not understood and, therefore, is ignored in textbooks. Evolutionists insist that it happened, though—because we are here. Multicellular protists, like algae, were the product of this process of diversification that happened at a time when the earth was supposedly going through many globecovering ice ages. The evolution of life is a miracle in itself, but the fact that it happened in an environment that alternated between freezer and oven conditions makes it all the more surprising. Evolutionists suggest that the multiple types of eukaryotic life, from protists to mammals, all arose from a common ancestor, but in several distinct lines. The lines that turned into algae and plants contained chlorophyll and mitochondria, and those that turned into animals contained only mitochondria (or may have lost their chlorophyll).
The most striking feature of this part of the evolutionary story is the lack of evidence. Life supposedly started hundreds of millions of years before the first fossils were formed. An understanding of how the three domains of living things (archaebacteria, eubacteria, and eukaryotes) are related has changed significantly. The rapid appearance of multicellular life seen in the Cambrian explosion produces more questions than answers, and the lack of fossil evidence does not support the claims made as to how life advanced into the forms we see today.
Another major event at this point in the evolutionary storyline is the arrival of sexual reproduction. No effective hypothesis can explain the origin of sexual reproduction. In his book Climbing Mount Improbable, Richard Dawkins, a leading evolutionary proponent, says:
To say, as I have, that good genes can benefit from the existence of sex whereas bad genes can benefit from its absence, is not the same thing as explaining why sex is there at all. There are many theories of why sex exists, and none of them is knock-down convincing … . Maybe one day I’ll summon up the courage to tackle it in full and write a whole book on the origin of sex.
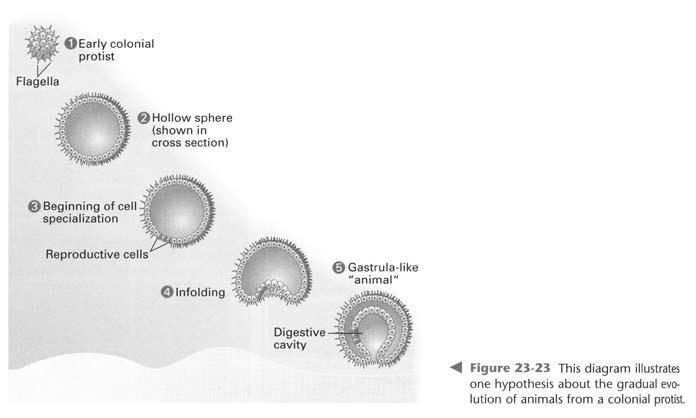
(PH-Campbell 514) Though this figure seems to present a scenario for the development of multicellular life, there is no evidence for its accuracy. The textbooks use phrases like “evolutionary milestone” and “appearance of key adaptations” to tell a story that has no basis in science. The textbooks make no attempt to explain how the genetic information developed that could allow a change from individuals to groups of cells exhibiting different developmental pathways and performing different tasks.
The evolution of sexual reproduction is rarely mentioned in textbooks or given more than a just-so statement of the fact that it happened. How two individuals of the same species could have acquired the mutations that would have led to only passing on half of their chromosomes, in a very complex process known as meiosis, and then mated at the exact same time and place in evolutionary history is nothing less than a miracle. The advantages to sexual reproduction are often provided as evidence for evolution, but the mechanism is rarely explained. Just because something would offer an advantage does not mean that it would develop.
Starting with the Bible as a foundation, the interpretation of the existence of single-celled and multicelled organisms is simple. Their apparent similarities point to a divine Creator, not a common ancestor. As we learn more about the complexity of living things and the record that has been left in the rocks, it becomes clearer that life did not evolve from simple to more complex organisms, but that they were created to reproduce “after their kind.”
Reference Articles
6:1 Supposed eukaryote evolution pushed back one billion years, Oard, https://answersingenesis.org/origin-of-life/supposed-eukaryote-evolution-pushed-back-one-billion-years/
Traces of compounds (hydrocarbons called “steranes”) produced by eukaryotes (single-celled organisms with membrane-bound organelles) found in 1999 pushed back the arrival of eukaryotes from 1.2 to 2.7 billion years ago. The evolutionary story that had supposed it was difficult for eukaryotes to evolve had to be dramatically reworked. This also presents a challenge to thinking about the early atmosphere because oxygen would have needed to be present to produce the compounds found. This is just another example of the history of life being dramatically changed based on new fossil evidence found and interpreted in the evolutionary framework. Of course, there is no need to change the creation model in light of this evidence. The organisms were all created at the same time and are expected to occur in the oldest sedimentary rocks correlating to the Flood.
6:2 Ancient organisms stay the same, Creation, June 1999, pp. 7–9.
A while ago, evolutionists would not have expected to find any fossils in rocks that they thought were, say, three billion years old—life supposedly hadn’t evolved yet. However, fossils of bacteria kept turning up in progressively older rocks (no surprise to creationists), which allowed less and less time for the first life to evolve in the hypothetical, oxygen-free early atmosphere. Now an Austrian/Swiss team of scientists has looked at rock from Western Australia’s Pilbara region, supposedly around 3.5 billion years old, and found fossilized cyanobacteria. These appear to be indistinguishable from the same (oxygen-producing) creatures making the mat structures called stromatolites in the shallows of Shark Bay, some 500 kilometers away on the coast.
6:3 “Snowball Earth”—a problem for the supposed origin of multicellular animals, Oard, https://answersingenesis.org/environmental-science/ice-age/a-problem-for-the-supposed-origin-of-multicellular-animals/
Evolutionary scientists suggest that several ice ages that occurred hundreds of millions to billions of years ago actually extended to the equator—the “snowball earth” hypothesis. A major problem is that the snowball condition would be permanent unless there was some catastrophic event to reverse it. Evolutionists face a major problem. Life was supposed to be evolving into multicellular forms at this time— a difficult task in light of a global ice age. Rock formations also suggest a very hot period immediately after, and sometimes during, these ice ages.
To accommodate this, a freeze-fry model was created that allowed the rapid diversification of multicellular life. Volcanoes penetrated the ice and spewed carbon dioxide into the atmosphere, increasing temperatures through the greenhouse effect. A rapid reversal of temperature provided an opportunity for organisms to diversify. Not only did this happen once but five times in the evolutionary model. These cycles limit the likelihood of evolution occurring even further. There are many other significant problems with the model, and computer simulations have failed to show its viability. Trying to explain the explosion of life at the beginning of the Cambrian Period while accommodating climate extremes has proven an impossible puzzle for evolutionists to solve. Creationists can explain the rock evidence in terms of underwater landslides and rock formation during the hot-ocean phase of the Genesis Flood. The abrupt appearance of multicellular organisms is also easily accounted for in the account of creation.
6:4 Round and round we go—proposed evolutionary relationships among archaea, eubacteria, and eukarya, Purdom, http://www.answersingenesis.org/articles/2006/10/04/evolutionary-relationships
In 1977 Carl Woese first identified what he called a third domain of life, named archaea, based on ribosomal RNA (rRNA) sequence comparisons. The other two domains of life are eubacteria (true bacteria, prokaryotes) and eukarya (protists, fungi, plants, animals, and humans). Archaea share some physical characteristics with eubacteria but tend to live in more extreme environments, such as hot springs and high-salt environments. These extreme environments were believed to be present on early earth; hence archaea were thought to be the ancestor to both eubacteria and eukarya. However, further analyses of archaea showed them to be genetically and biochemically quite different from eubacteria, and they are no longer believed to be ancestral to eubacteria.
Archaea are actually more genetically similar to eukaryotes than eubacteria and are often represented as a “sister” to eukarya on evolutionary trees of life. Eukarya have genes that appear to have come from both archaea and eubacteria, and so a genome fusion has been proposed. Archaea have given eukarya their informational genes (genes for transcription, translation, etc.), and eubacteria have given eukarya their operational genes (genes for amino acid biosynthesis, fat biosynthesis, etc.). Rather than an evolutionary “tree” of life, a “ring” of life has been suggested. The archaea and eubacteria (possibly multiple ones) fused using the processes of endosymbiosis and lateral gene transfer to give rise to eukarya.
A subheading in a recent article discussing the challenges of determining evolutionary relationships among these three groups says it well: “More good theories for eukaryotic origins than good data.” The scientists are so locked into their evolutionary assumptions that they must keep reinterpreting the data to fit their theories. If they would interpret their data in light of the truth found in the Bible, they would find that the data fits the creation model much better.
God created many individual kinds of archaea, eubacteria, and eukarya. Through the processes of natural selection and speciation, the many different bacterial, plant, and animal species we have today have developed. The common traits seen among these living organisms point to a common designer not a common ancestor.
6:5 Shining light on the evolution of photosynthesis, Swindell, https://answersingenesis.org/evidence-against-evolution/shining-light-on-the-evolution-of-photosynthesis/
The evolution of photosynthesis appears to be an impossible process as the intermediate products are toxic to the cell. In the absence of all of the enzymes being present at once, the process would kill the cells it was happening in. The probability of all of the enzymes evolving simultaneously makes it virtually impossible that photosynthesis occurred by chance in “primitive” bacteria. This article describes the process of photosynthesis to expose the evolutionary hurdles that would need to be overcome. The challenges to the evolution of photosynthesis include the presence of 17 enzymes required to assemble chlorophyll and the toxicity of intermediate molecules required to chemically synthesize the enzymes. Natural selection cannot explain the presence of useless enzymes waiting for a functional product, or the presence of other irreducibly complex components.
It defies common sense to imagine that the irreducible complexity of photosynthetic systems would have formed according to evolutionary theory. Rather, the incredible organization and intricacy evident in photosynthesis—a process man has yet to fully understand, let alone copy— screams for a designer. If photosynthesis was present from the beginning, the “oxygen revolution” was never a condition that evolving life had to deal with. Having been created by God, life on earth was already equipped to deal with such issues.
6:6 “Nonevolution” of the appearance of mitochondria and plastids in eukaryotes—challenges to endosymbiotic theory, Purdom, http://www.answersingenesis.org/articles/2006/10/11/endosymbiotic-theory
Endosymbiont theory was first developed and popularized by Lynn Margulis in the early 1980s. The idea proposes that mitochondria were originally protobacteria that were engulfed by an ancestral cell but not digested. As a result, this ancestral cell became heterotrophic (i.e., human and animal cells). Plastids (i.e., chloroplasts) were originally cyanobacteria that were engulfed by an ancestral cell but not digested. This ancestral cell became autotrophic (i.e., plants). These organelles share some characteristics with bacteria including circular DNA, division by binary fission, and membrane and ribosome similarities.
On the surface this process seems simple, but these organelles and their relationship to the cell are extremely complex. For example, not all the proteins necessary for the functioning of the organelles are found in their own genomes. Instead, some of the protein codes are found in the nucleus of the cell. Organelle proteins not made in the organelle must be transferred into the organelle. This involves complex protein transfer machinery comprised of multiple pathways, each involving numerous proteins for the transport of proteins into mitochondria and plastids. How does a transport pathway made of multiple parts, all necessary for the proper functioning of that pathway, evolve in slow incremental steps? It can’t because of evolution’s “use it or lose it” mechanism; so it must have been designed by a Creator God all at once and fully functional.
6:7 Evolutionary theories on gender and sexual reproduction, Harrub and Thomson, www.trueorigin.org/sex01.php
One concept that is rarely mentioned in the evolutionary storytelling is the origin of sexual reproduction (sex). The idea of survival of the fittest seems to fail to explain the origin of sex, even if it may be able to explain why it would be maintained once it had developed. Asexual reproduction is a very effective method of reproduction compared to sex. Several hypotheses have been proposed to explain the origin of sex.
The Lottery Principle suggests that asexual reproduction is like buying many lottery tickets with the same number. Sex allows a mixing of genes; so it is like buying many tickets with many different number combinations.
The Tangled Bank Hypothesis suggests that sex originated to simply prepare the offspring for the variety of challenges they would face in the environment. The intense competition makes sex an advantage.
The Red Queen Hypothesis suggests that sex gives the offspring an advantage in the constant competition to simply maintain its position in the “genetic arms race.” Organisms must be constantly undergoing genetic changes just to be able to continue to survive in their environment— they must constantly run just to stay in place. Sex would certainly be an advantage in such a scenario.
The DNA Repair Hypothesis suggests that an advantage is obtained if an organism has two copies of any given gene. The bad copy is less likely to cause problems if there is a chance that the other copy is good. The more genes you have, the less likely you are to suffer from genetic diseases. This would prevent bad genes from affecting a population rapidly and provide a mechanism for the preservation of favorable traits.
Each of these hypotheses, or some combination of them, provides a reasonable explanation for the benefit of sex once it is present, but none address its actual origin. Just because something has a benefit does not mean that it must happen. Neither do these hypotheses address the physical development of male and female sex organs and behaviors. The language used by evolutionists when discussing the particulars of the origin of sex is riddled with phrases like “perhaps some could,” “may have been,” “by chance,” and “over time.” All of these are devoid of any evidence. The highly complex nature of sexual reproduction and life on earth clearly points to God as the Intelligent Creator.
Questions to Consider
- How, exactly, did sexual reproduction originate?
- Do scientists just accept that sexual reproduction must have evolved because it exists, even though they can’t explain how it happened?
- Sexual reproduction certainly has advantages, but how did the first two sexually reproducing organisms obtain all of the abilities needed at the same time? Males and females would have had to evolve simultaneously while still reproducing to continue the survival of the species.
- Since multicellular animals evolved at multiple times, wouldn’t sexual reproduction have to evolve independently several times? How likely is it that the same process (meiosis) would develop multiple times in the same way?
- Since all the components of the first cell came from the environment, how did it get the ability (information) to make or assemble these components?
- Since there is no evidence of life before 3.5 billion years ago, how can we be sure it was there? Is this an example of faith?
- Since the nuclear membrane is intended to prevent DNA contamination, how did a bacterium get its DNA into the nucleus of another cell and then evolve into a chloroplast or mitochondria?
Tools for Digging Deeper
(see a complete list in the Introduction)
Darwin’s Black Box by Michael Behe
In the Beginning Was Information by Werner Gitt
The Biotic Message by Walter ReMine
Evolution Exposed: Biology

This book helps teens discern the chronic bias towards belief in evolution that permeates today’s three most popular high school biology textbooks.
Read Online Buy Book
Master Books has graciously granted AiG permission to publish selected chapters of this book online. To purchase a copy please visit our online store.

Support the creation/gospel message by donating or getting involved!

Answers in Genesis is an apologetics ministry, dedicated to helping Christians defend their faith and proclaim the good news of Jesus Christ.
- Customer Service 800.778.3390
- Available Monday–Friday | 9 AM–5 PM ET
- © 2026 Answers in Genesis