

Chapter 6
Information in Living Organisms
by
Dr. Werner Gitt
on
April 2, 2009
Republished with permission and featured in
In the Beginning Was Information
There is an extreme multiplicity of life-forms around us, and even a simple unicellular organism is much more complex and purposefully designed than anything that human inventiveness can produce. Matter and energy are basic prerequisites for life, but they cannot be used to distinguish between living and inanimate systems. The central characteristic of all living beings is the “information” they contain, and this information regulates all life processes and procreative functions. Transfer of information plays a fundamental role in all living organisms. When, for example, insects carry pollen from one flower to another, this is in the first place an information-carrying process (genetic information is transferred); the actual material employed is of no concern. Although information is essential for life, information alone does not at all comprise a complete description of life.
Man is undoubtedly the most complex information-processing system existing on earth. The total number of bits handled daily in all information-processing events occurring in the human body is 3 x 1024. This includes all deliberate as well as all involuntary activities, the former comprising the use of language and the information required for controlling voluntary movements, while the latter includes the control of the internal organs and the hormonal systems. The number of bits being processed daily in the human body is more than a million times the total amount of human knowledge stored in all the libraries of the world, which is about 1018 bits.
6.1 Necessary Conditions for Life
The basic building blocks of living beings are the proteins, which consist of only 20 different amino acids. These acids have to be arranged in a very definite sequence for every protein. There are inconceivably many possible chains consisting of 20 amino acids in arbitrary sequences, but only some very special sequences are meaningful in the sense that they provide the proteins which are required for life functions. These proteins are used by and built into the organism, serving as building materials, reserves, bearers of energy, and working and transport substances. They are the basic substances comprising the material parts of living organisms and they include such important compounds as enzymes, anti-bodies, blood pigments, and hormones. Every organ and every kind of life has its own specific proteins and there are about 50,000 different proteins in the human body, each of which performs important functions. Their structure as well as the relevant “chemical factories” in the cells have to be encoded in such a way that protein synthesis can proceed optimally, combining the correct quantities of the required substances.
The structural formulas of the 20 different amino acids that serve as chemical building blocks for the proteins found in all living beings appear in the book In sechs Tagen vom Chaos zum Men-schen [G10, p. 143]. If a certain specific protein must be manufactured in a cell, then the chemical formula must be communicated to the cell as well as the chemical procedures for its synthesis. The exact sequence of the individual building blocks is extremely important for living organisms, so that the instructions must be in written form. This requires a coding system as well as the necessary equipment which can decode the information and carry out the instructions for the synthesis. The minimal requirements are:
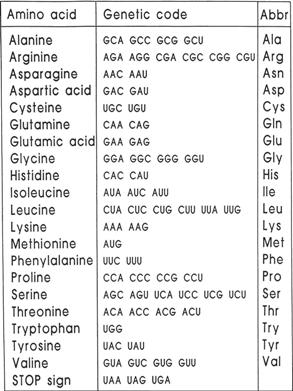
Figure 16: The 20 amino acids which are present in living systems, given in alphabetic order, together with their international three-letter abbreviations. The code combinations (triplets) which give rise to the relevant acid are indicated in the right-hand column.
—According to Theorem 6, a coding system is required for compiling information, and this system should be able to identify uniquely all the relevant amino acids by means of a standard set of symbols which must remain constant.
—As required by Theorems 14, 17, and 19, for any piece of information, this information should involve precisely defined semantics, pragmatics, and apobetics.
—There must be a physical carrier able to store all the required information in the smallest possible space, according to Theorem 24.
The names of the 20 amino acids occurring in living beings and their internationally accepted three-letter abbreviations are listed in Figure 16 (e.g., Ala for alanine). It is noteworthy that exactly this code with four different letters is employed; these four letters are arranged in “words” of three letters each to uniquely identify an amino acid. Our next endeavor is to determine whether this system is optimal or not.
The storage medium is the DNA molecule (deoxyribonucleic acid), which resembles a double helix as illustrated in Figure 17. A DNA fiber is only about two millionths of a millimeter thick, so that it is barely visible with an electron microscope. The chemical letters A, G, T, and C are located on this information tape, and the amount of information is so immense in the case of human DNA that it would stretch from the North Pole to the equator if it was typed on paper, using standard letter sizes. The DNA is structured in such a way that it can be replicated every time a cell divides in two. Each of the two daughter cells must have identically the same genetic information after the division and copying processes. This replication is so precise that it can be compared to 280 clerks copying the entire Bible sequentially, each one from the previous one, with, at most, one single letter being transposed erroneously in the entire copying process.
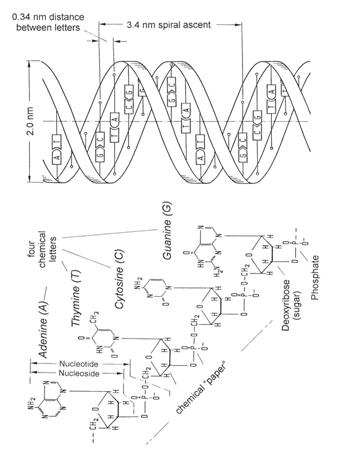
Figure 17: The way in which genetic information is stored. At the left, the “chemical paper” is shown in the form of a long sugar-phosphate chain with the four chemical letters, A, T, C, and G. The actual structure and dimensions of a DNA molecule can be seen at the top.
When a DNA string is replicated, the double strand is unwound, and at the same time a complementary strand is constructed on each separate one, so that, eventually, there are two new double strands identical to the original one. As can be seen in Figure 17, A is complementary to T, and C to G.
One cell division lasts from 20 to 80 minutes, and during this time the entire molecular library, equivalent to one thousand books, is copied correctly.
6.2 The Genetic Code
We now discuss the question of devising a suitable coding system. For instance, how many different letters are required and how long should the words be for optimal performance? If a certain coding system has been adopted, it should be strictly adhered to (theorem 8, par 4.2), since it must be in tune with extremely complex translation and implementation processes. The table in Figure 19 comprises only the most interesting 25 fields, but it can be extended indefinitely downward and to the right. Each field represents a specific method of encoding, for example, if n = 3 and L = 4, we have a ternary code with 3 different letters. In that case, a word for identifying an amino acid would have a length of L = 4, meaning that quartets of 4 letters represent one word. If we now want to select the best code, the following requirements should be met:
—The storage space in a cell must be a minimum so that the code should economize on the required material. The more letters required for each amino acid, the more material is required, as well as more storage space.
—The copying mechanism described above requires n to be an even number. The replication of each of the two strands of DNA into complementary strands thus needs an alphabet having an even number of letters. For the purpose of limiting copying errors during the very many replication events, some redundance must be provided for (see appendix A 1.4).
—The longer the employed alphabet, the more complex the implementing mechanisms have to be. It would also require more material for storage, and the incidence of copying errors would increase.

Figure 18: The chemical formula of insulin. The A chain consists of 21 amino acids and the B chain is comprised of 30 amino acids. Three of the 20 amino acids present in living organisms, are absent (Asp, Met, Try), two occur six times (Cys, Leu), one five times (Glu), three occur four times (Gly, Tyr, Val), etc. The two chains are linked by two disulphide bridges. Insulin is an essential hormone, its main function being to maintain the normal sugar content of the blood at 3.9 to 6.4 mmol/l (70–115 mg/dl).
In each field of Figure 19, the number of possible combinations for the different words appears in the top left corner. The 20 amino acids require at least 20 different possibilities and, according to Shannon’s theory, the required information content of each amino acid could be calculated as follows: For 20 amino acids, the average information content would be iA ≡ iW ≡ ld 20 = log 20/log 2 = 4.32 bits per amino acid (ld is the logarithm with base 2).
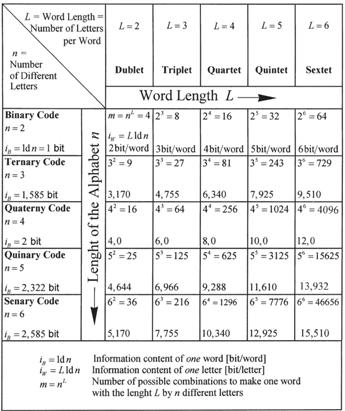
Figure 19: The theoretical possibility of constructing a code consisting of words of equal length. Every field (block) represents a definite coding system as indicated by the number of different letters n, and the word length L.
If four letters (quartets) are represented in binary code (n = 2), then (4 letters per word)x(1 bit per letter) = 4 bits per word, which is less than the required 4.32 bits per word. This limit is indicated by the hatched boundary in Figure 19. The six fields adjacent to this line, numbered 1 to 6, are the best candidates. All other fields lying further to the right could also be considered, but they would require too much material for storage. So we only have to consider the six numbered cases.
It is, in principle, possible to use quintets of binary codes, resulting in an average of 5 bits per word, but the replication process requires an even number of symbols. We can thus exclude ternary code (n = 3) and quinary code (n = 5). The next candidate is binary code (No. 2), but it needs too much storage material in relation to No. 4 (a quaternary code using triplets), five symbols versus three implies a surplus of 67%. At this stage, we have only two remaining candidates out of the large number of possibilities, namely No. 4 and No. 6. And our choice falls on No. 4, which is a combination of triplets from a quaternary code having four different letters. Although No. 4 has the disadvantage of requiring 50% more material than No. 6, it has advantages which more than compensate for this disadvantage, namely:
—With six different symbols, the recognition and translation requirements become disproportionately much more complex than with four letters, and thus requires much more material for these purposes.
—In the case of No. 4, the information content of a word is 6 bits per word, as against 5.17 bits per word for No. 6. The resulting redundancy is thus greater, and this ensures greater accuracy for the transfer of information.
Conclusion: The coding system used for living beings is optimal from an engineering standpoint. This fact strengthens the argument that it was a case of purposeful design rather than fortuitous chance.
6.3 The Origin of Biological Information
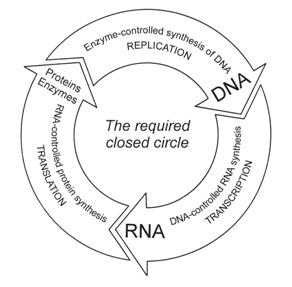
Figure 20: A simplified representation of the cyclic information controlled process occurring in living cells. The translation is based on pragmatics, but it is involved in the cyclic process of semantic information, since the DNA synthesis can only take place under enzymatic catalysis. This sketch clearly illustrates that such a cyclic process must have been complete right from the start, and could not have originated in a continuous process. The structure of this example of a complex information transfer system also corresponds to Figure 24.
We find a unique coding system and a definite syntax in every genome.1 The coding system is composed of four chemical symbols for the letters of the defined alphabet, and the syntax entails triplets representing certain amino acids. The genetic syntax system also uses structural units like expressors, repressors, and operators, and thus extends far beyond these two aspects (4 symbols and triplet words). It is not yet fully understood. It is known that the information in a cell goes through a cyclic process (Figure 20), but the semantics of this process is not (yet) understood in the case of human beings. The locations of many functions of chromosomes or genes are known, but we do not yet understand the genetic language. Because semantics is involved, it means that pragmatics also have to be fulfilled. The semantics are invariant, as can be seen in the similarity (not identity!) of uni-ovular twins. If one carefully considers living organisms in their entirety as well as in selected detail, the purposefulness is unmistakable. The apobetics aspect is thus obvious for anybody to see; this includes the observation that information never originates by chance, but is always conceived purposefully.
The substitutionary function of information is also satisfied (see Definition D5 in chapter 5), since the triplets in the DNA molecule represent those amino acids that will be synthesized at a later stage for incorporation into proteins (the amino acids themselves are not present). We can now establish an important theorem:
Theorem 25: Biological information is not an exceptional kind of information, but it differs from other systems in that it has a very high storage density and that it obviously employs extremely ingenious concepts.
In accordance with the theorems formulated in chapters 3 to 5, in particular the impossibility theorems at the end of chapter 4, it is clear that the information present in living organisms requires an intelligent source. Man could not have been this source; so, the only remaining possibility is that there must have been a Creator. We can now formulate the following theorems:
Theorem 26: The information present in living beings must have had a mental source.
A corollary of Theorem 26 is:
Theorem 27: Any model for the origin of life (and of information) based solely on physical and/or chemical processes, is inherently false.
In their school textbook, R. Junker and S. Scherer establish a basic type that must have been “ready-made” [J3]. This result, which requires the information content of living beings to be complete right from the beginning, is biologically sound. The derived theorems about the nature of information fit this model.
6.4 Materialistic Representations and Models of the Origin of Biological Information
The question “How did life originate?” which interests us all, is inseparably linked to the question “Where did the information come from?” Since the findings of James D. Watson (*1928) and Francis H.C. Crick (*1916), it was increasingly realized by contemporary researchers that the information residing in the cells is of crucial importance for the existence of life. Anybody who wants to make meaningful statements about the origin of life would be forced to explain how the information originated. All evolutionary views are fundamentally unable to answer this crucial question.
The philosophy that life and its origin are purely material phenomena currently dominates the biological sciences. Following are the words of some authors who support this view.
Jean-Baptiste de Lamarck (1744–1829), a French zoologist and philosopher, wrote, “Life is nothing but a physical phenomenon. All life features originate in mechanical, physical, and chemical processes which are based on the properties of organic matter itself ” (Philosophie Zoologique, Paris, 1809, Vol. 1).
The German microbiologist R.W. Kaplan holds a similar materialistic view [K1]: “Life is effected by the different parts of a system which work together in a certain way. . . . Life can be completely explained in terms of the properties of these parts and their inevitable interactions. . . . The origin of life can be explained in terms of hypotheses describing fully the sequence of events since the origin of protobionts, and the fact that all these events could be deduced from physical, chemical, and other laws which are valid for material systems.”
Manfred Eigen (*1927), a Nobel laureate of Göttingen, discusses questions about life from the molecular biology view, with as point of departure the unwarranted postulate that natural laws controlled the origin of life. In his work on the self-organization of matter [E1], he uses an impressive array of formulas, but does not rise above the level of statistical information. This voluminous work is thus useless and does not answer any questions about the origin of information and of life. He writes in [E2, p 55], “Information arises from non-information.” This statement is nothing but a confession of materialism, and it fails the tests required by reality.
Franz M. Wuketits defines the target readership of his book [W8] as follows: “. . . not only biologists and theoretical scientists, but in equal measure scientists and philosophers, and everybody who is interested in the adventures of contemporary science.” He then presents a so-called “evolutionary theoretical science,” claiming to initiate a new Copernican revolution. Up to the present time, great scientific results were obtained by means of observation, measuring, and weighing, as was done for example by Copernicus, Galilei, Newton, Einstein, Born, and Planck. In his system, Wuketits follows the backward route: His point of departure is to assume that evolution is true, so that all natural phenomena have to be interpreted through these spectacles. He writes in the introduction of his book [W8, p. 11–12]:
The fundamental truth of biological evolution is accepted beforehand, yes, we assume in advance that the principle of evolution is universally valid, that it is just as valid in the preorganic domain as in the organic, and that it can be extended to the spheres of psychology, sociology, and culture. If we accept that the evolutionary view also holds for the human mind and cognition, then evolutionary ideas can also be applied to the analysis of those phenomena which are usually regarded as belonging to theoretical science. As a result this view then becomes relatively more important in the evaluation of the progress of scientific research. We thus arrive at an evolutionary theory of science, a theory of human knowledge which relates to an evolutionary establishment of itself.
If such statements were based on a sufficient body of facts, then one might perhaps agree with the conclusions, but the reverse process was followed: All phenomena of nature are placed under the all-encompassing evolutionary umbrella. Scientists who submit themselves to such a mental corset and support it uncritically, degrade themselves to mere vassals of a materialistic philosophy. Science should, however, only be subservient to the truth, and not to pre-programmed folly. Evolutionary theory bans any mention of a planning Spirit as a purposeful First Cause in natural systems, and endeavors to imprison all sciences in the straightjacket called the “self-organization of matter.” Wuketits supports evolutionary theory with a near ideological fervor, and accuses everybody of fable mongering who claims to be scientific and speak of “planning spirits” or of a “designer” in nature. He wishes to ban thoughts of “finality” and of “final and purposeful causes” from science and from the domain of all serious schools of thought.
An appreciable fraction of all scientists who concern themselves with cosmological questions and with questions of origins, support the evolutionary view, to such an extent that the well-known American bio-informaticist Hubert P. Jockey [J1] bemoans the fact that the literature in this area is blandly and totally supportive. He writes in the Journal of Theoretical Biology [vol. 91, 1981, p. 13]:
Since science does not have the faintest idea how life on earth originated. . . . it would only be honest to confess this to other scientists, to grantors, and to the public at large. Prominent scientists speaking ex cathedra, should refrain from polarizing the minds of students and young productive scientists with statements that are based solely on beliefs.
The doctrine of evolution is definitely not a viable scientific leitmotiv (guiding principle); even the well-known theoreticist Karl Popper [H1], once characterized it as a “metaphysical research program.” This assertion is just as noteworthy as it is honest, because Popper himself supports evolution.
We now discuss some theoretical models which suggest that information can originate in matter.
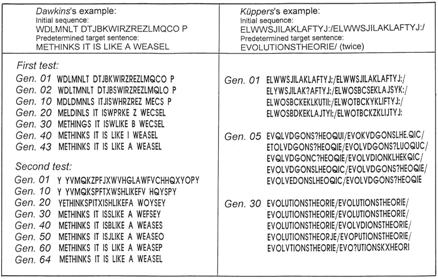
Figure 21: Molecular-Darwinistic representations of the origin of information according to R. Dawkins and B.O. Küppers.
Cumulative selection (Latin cumulare = gather): Richard Dawkins, a British neo-Darwinist, revives the historical example of the typewriter-thrumming monkeys (see appendix A1.5) and replaces them with “computer monkeys.” As shown in Figure 21, he begins with a random sequence of 28 letters [D2 p. 66–67] and seeks to demonstrate how a predetermined phrase selected from Shakespeare, “Methinks it is like a weasel,” can be derived through mutation and selection. The random initial sequence with the required number of letters is copied repeatedly, allowing for random copying errors (representing mutations). The computer program checks all the “daughter” sentences and selects that one which most resembles the target sentence. The process is subsequently repeated for the resulting “winning sentences,” until eventually, after 43 “generations,” the goal is reached.
There is a spate of new Jesus books which constantly present strange new and false ideas contrary to the New Testament. Prof. Klaus Berger of the Heidelberg School of Theology remarked (1994): “Please buy and read such a book, then you will realize what degree of gullibility is ascribed to you.” With equal zeal, Dawkins publishes his easily detectable fallacies about the way information originates. It is therefore necessary to discuss his representation fully so that you, the reader, can see what feeble-mindedness is ascribed to you.
In the initial pages of his book, Dawkins [D2, p. 13] softens the reader to the purposelessness of living structures: “Biology is the study of complex matters that appear to have been designed purposefully.” Further along he selects a target sentence and his entire program is designed toward this goal. This game can be played with any random initial sequence and the goal will always be reached, because the programming is fixed. Even the number of letters is given in advance. It is obvious that no information is generated; on the contrary, it has been predetermined. B.O. Küppers plays a similar evolution game [K3]: The predetermined target word is evolutionstheorie appearing twice (see the right hand part of Figure 21). It should be clear from Theorem 27 that random processes cannot give rise to information.
Genetic algorithms: The so-called “genetic algorithms” are yet another way of trying to explain how information could originate in matter [F5, M4]. The combination of words is deliberately chosen from biology and numerical mathematics to suggest that evolutionary events are described mathematically. What is actually involved is a purely numerical method used for the optimization of dynamic processes. This method can be used to find, by repeated approximations, the maximum value of an analytic function numerically (e.g., f(x,y) = yx - x4), or the optimal route of a commercial traveler. The effects of mutation and selection can thus be simulated by computer. Using predetermined samples of bits (sequences of noughts and ones), each position is regarded as a gene. The sample is then modified (mutated) by allowing various genetic operators to influence the bit string (e.g., crossover). A “fitness function,” assumed for the process of evolution, is then applied to each result. It should be pointed out that this genetic algorithm is purely a numerical calculation method, and definitely not an algorithm which describes real processes in cells. Numerical methods cannot describe the origin of information.
Evolutionary models for the origin of the genetic code: We find proposals for the way the genetic code could have originated in very many publications [e.g., O2, E2, K1], but up to the present time, nobody has been able to propose anything better than purely imaginary models. It has not yet been shown empirically how information can arise in matter, and, according to Theorem 11, this will never happen.
6.5 Scientists Against Evolution
Fortunately, the number of scientists who repudiate evolutionary views and dilemmas is increasing. This number includes internationally renowned experts, of whom some quotations follow. In New Scientist, the British astrophysicist Sir Fred Hoyle, one of today’s best known cosmologists, expresses his concern about the customary representations under the title “The Big Bang in Astronomy” [H4, p. 523–524]:
But the interesting quark transformations are almost immediately over and done with, to be followed by a little rather simple nuclear physics, to be followed by what? By a dull-as-ditchwater expansion which degrades itself adiabatically until it is incapable of doing anything at all. The notion that galaxies form, to be followed by an active astronomical history, is an illusion. Nothing forms, the thing is as dead as a door-nail. . . . The punch line is that, even though outward speeds are maintained in a free explosion, internal motions are not. Internal motions die away adiabatically, and the expanding system becomes inert, which is exactly why the big-bang cosmologies lead to a universe that is dead-and-done-with almost from its beginning.
These views correspond with the findings of Hermann Schneider, a nuclear physicist of Heidelberg, who has critically evaluated the big bang theory from a physical viewpoint. He concludes [S5]: “In the evolution model the natural laws have to describe the origin of all things in the macro and the micro cosmos, as well as their operation. But this overtaxes the laws of nature.”
Fred Hoyle makes the following remarks about the much-quoted primeval soup in which life supposedly developed according to evolutionary expectations [H4, p 526]:
I don’t know how long it is going to be before astronomers generally recognize that the combinatorial arrangement of not even one among the many thousands of biopolymers on which life depends could have been arrived at by natural processes here on the earth. Astronomers will have a little difficulty at understanding this because they will be assured by biologists that it is not so, the biologists having been assured in their turn by others that it is not so. The “others” are a group of persons who believe, quite openly, in mathematical miracles. They advocate the belief that tucked away in nature, outside of normal physics, there is a law which performs miracles.
In his book Synthetische Artbildung (The Synthetic Formation of Kinds), Professor Dr. Heribert Nilsson, a botanist at Lund University in Sweden, describes evolutionary doctrine as an obstacle which prevents the development of an exact biology:
The final result of all my researches and discussions is that the theory of evolution should be discarded in its entirety, because it always leads to extreme contradictions and confusing consequences when tested against the empirical results of research on the formation of different kinds of living forms and related fields. This assertion would agitate many people. Moreover: my next conclusion is that, far from being a benign natural-philosophical school of thought, the theory of evolution is a severe obstacle for biological research. As many examples show, it actually prevents the drawing of logical conclusions from even one set of experimental material. Because everything must be bent to fit this speculative theory, an exact biology cannot develop.
Professor Dr. Bruno Vollmert of Karlsruhe, an expert in the field of macro-molecular chemistry, has shown that all experiments purporting to support evolution miss the crux of the matter [V1]:
All hitherto published experiments about the poly-condensation of nucleotides or amino acids are irrelevant to the problem of evolution at the molecular level, because they were based on simple monomers, and not on “primeval soups” derived from Miller experiments. But poly-condensation experiments with primeval soups or the dissolved mix of substances of them are just as superfluous as attempts to construct perpetual motion machines.
A French Nobel laureate, A. Lwoff [L2], pointed out that every organism can only function in terms of the complex net of available information:
An organism is a system of interdependent structures and functions. It consists of cells, and the cells are made of molecules which have to cooperate smoothly. Every molecule must know what the others are doing. It must be able to receive messages and act on them.
When considering the source of this information, we can now formulate the following theorem which is based on research of many thousands of man-years:
Theorem 28: There is no known law of nature, no known process, and no known sequence of events which can cause information to originate by itself in matter.
This was also the conclusion of the seventh “International Conference on the Origins of Life” held together with the fourth congress of the “International Society for the Study of the Origin of Life (ISSOL)” in Mainz, Germany. At such occasions, scientists from all over the world exchange their latest results. In his review of the congress, Klaus Dose [D3] writes: “A further puzzle remains, namely the question of the origin of biological information, i.e., the information residing in our genes today.” Not even the physical building blocks required for the storage of the information can construct themselves: “The spontaneous formation of simple nucleotides or even of polynucleotides which were able to be replicated on the pre-biotic earth should now be regarded as improbable in the light of the very many unsuccessful experiments in this regard.”
As early as 1864, when Louis Pasteur addressed the Sorbonne University in Paris, he predicted that the theory of the spontaneous generation of living cells would never recover from the fatal blow delivered by his experiments. In this regard, Klaus Dose makes an equally important statement: “The Mainz report may have an equally important historical impact, because for the first time it has now been determined unequivocally by a large number of scientists that all evolutionary theses that living systems developed from poly-nucleotides which originated spontaneously, are devoid of any empirical base.”
In the Beginning Was Information

Between the covers of this book may well be the most devastating scientific argument against the idea that life could form by natural processes.
Read Online
Master Books has graciously granted AiG permission to publish selected chapters of this book online. To purchase a copy please visit our online store.
Footnotes
- Genome (Greek génos = generation, kind, inheritance): the simple (haploid) complement of chromosomes of a cell; the totality of all the genes of a cell.

Support the creation/gospel message by donating or getting involved!

Answers in Genesis is an apologetics ministry, dedicated to helping Christians defend their faith and proclaim the good news of Jesus Christ.
- Customer Service 800.778.3390
- Available Monday–Friday | 9 AM–5 PM ET
- © 2026 Answers in Genesis